Pronouns: Students’ Worst Enemy in the Foreign Language Classroom
Los pronombres: el peor enemigo de los estudiantes en clase de lengua extranjera
RESUMEN
Este artículo reporta los resultados de un estudio en el que se buscaba la categoría léxico-gramatical con más errores en un corpus de 90 redacciones en español escritas por estudiantes angloparlantes matriculados en los cursos de 2º, 3º y 4º semestre a nivel universitario. Se usó la técnica de análisis de errores y la creación de una taxonomía para contar, identificar, describir y clasificar los errores. Sorprendentemente, la categoría con más errores (vs. formas correctas) no fue verbos, como se esperaba, sino pronombres en 2º y 4º, así como la segunda con más errores en 3º. El artículo describe qué tipo de errores se encontraron, cómo evolucionaron de semestre a semestre y sus posibles causas. Se incluyen algunas recomendaciones pedagógicas, como la necesidad de dar más instrucción en clase sobre este tema tan complicado.
Palabras clave: Estudiantes ELE, Análisis de errores, taxonomia, Interlengua, linguistica de corpus, competencia escrita
ABSTRACT
In the Spanish-as-a-foreign-language class, there is a vast amount of classroom instruction (and textbook attention) dedicated to verbs, assuming that this is the most difficult issue for native English speakers to learn. A research study was carried out to confirm this common assumption. Error analysis was used and a lexico-grammatical taxonomy was created to count, identify, describe and classify the written errors found in ninety unaided compositions from 2nd-, 3rd-, and 4th-semester courses. Surprisingly, the category with the highest internal error rate in 2nd- and 4th-semester courses and the second highest in 3rd-semester courses was pronouns. A description of errors by type and their evolution from one semester to the next is included. An obvious cause for errors was found to be the interference of the L1. Pedagogical implications include the need to strengthen instruction of this apparently neglected category of pronouns at all levels of proficiency.
Keywords: learner corpus, taxonomy, interlanguage, error analysis, corpus linguistics, written error
Fecha de recepción: 12 septiembre de 2013
Fecha de aceptación: 1 noviembre de 2013
1. Introducción
Research and classroom experience show that English-speaking students make many written errors with verbs. Learning Spanish verbal forms is considered a difficult issue for any English-speaking student. Textbooks dedicate a lot of space to verbs and many curricula are organized according to verbal moods and tenses. However, is this really the most difficult foreign language issue for students? One cannot help but wonder if there are other parts of speech or other issues just as difficult that are being neglected both in textbooks and in classroom instruction due to this overwhelming attention that verbs usually receive.
Assuming that errors are just the evidence that a learner is having difficulties acquiring or learning a specific concept, the purpose of this study is to analyze students’ written errors in order to find out the most difficult lexico-grammatical categories, so that instruction can be properly geared towards those categories.
1.1. Error analysis
Since S. P. Corder’s (1967) seminal article on the importance of errors in learning, teaching and research, error analysis (EA) has been a helpful technique to identify areas where students are having problems with the objective of strengthening instruction on those areas and / or accommodating teaching methods appropriately. In this study, the term error –as opposed to mistake—will be used in the way he described it, as a systematic type of failure, not as a failure due to “memory lapses, physical states such as tiredness, and psychological conditions such as strong emotion” (p. 168). Just because this technique was widely used in the 1970s, it does not mean that 21st-century instructors cannot take advantage of its useful benefits for today’s teaching.
EA is “a comparison made between the errors a learner makes in producing the target language and the target language from itself” (Gass & Selinker 2001, p. 79) or “the process of determining the incidence, nature, causes and consequences of unsuccessful language” (James 1998, p. 1). Errors must be seen as evidence of the progressive acquisition process, the development of the students’ interlanguage. As Fernández (1997) states, errors are valued, “además de como paso obligado para llegar a apropiarse de la lengua, como índices del proceso que sigue el aprendiz en ese camino” [besides as a mandatory step to appropriate the language, as evidence of the process that the learner endures on the way] (p. 18).
The procedure by which students’ errors are investigated is the following: first, the researcher pays attention to the actual corpus of errors created by students and attempts to identify, classify and describe these errors, and maybe even explain their causes. This information is conveyed in the form of a classification or taxonomy. Johnson and Johnson (1999) describe a taxonomy as a system to identify, describe, and classify errors. Santos Gargallo (1993) states that this inventory or typology of most common errors has as objective to identify areas that are difficult for a specific group of learners. Taxonomies basically have two different designs, according to Dulay, Burt and Krashen (1982): In the cross-sectional design, which is synchronic in nature, errors are collected from a large sample of learners at a specific point in time; in the longitudinal design, which is diachronic in nature, errors are collected from a small group of learners at different points in time. Both designs provide useful information on the frequency, type and evolution of errors. See Dulay, Burt and Krashen (1982) and James (1998) for a full description of different types of taxonomies depending on the classification criteria.
Although taxonomies are believed to be great tools by most researchers, they are not flawless. For example, taxonomies do not show errors when students avoid to write specific structures or items (Diaz Villa 2005; Schachter 1974) and they have other weak aspects that could turn them into confusing and misleading tools (Dulay et al. 1982). In addition, the great variety of criteria used to create taxonomies makes it very difficult to compare studies and arrive at common conclusions (Alba Quiñones 2009). Despite these flaws, taxonomies are valued because they show errors and errors are considered to be an essential part in the process of learning any language (Martínez Guillem 2010).
2. Literature review
In this section, I will only cover the most important studies that used lexico-grammatical taxonomies in courses of Spanish as a foreign and as a second language.
One of the earliest studies is Azevedo (1980). He examined lexico-grammatical errors found in 61 papers written by English-speaking graduate students of Spanish. Some errors found include gender and number agreement in passive constructions, making the indirect object the passive subject, confusing the impersonal and passive “se”, misuse of the reflexive pronoun, the “gustar” structure, confusing the preterit and the imperfect, and gender assignment for words ending in consonant or for exceptions to the rule (e.g., el problema), among others. He found prepositions to be a problematic category. Also, single words that have two equivalents in the second language (L2) were a major source of errors, such as por/para. “When an item in the native tongue has two structural counterparts in the target language, there is fifty per cent probability that the wrong choice will be made” (Azevedo 1980, p. 221). Like Dušková (1969), he found many errors in a category that does not exist in the first language (L1), like the definite article.
Barnwell (1987) only examined the errors found in verbal aspect selection from 85 midterm exams written by university English-speaking students of second-semester Spanish. Results showed that students had more errors in selecting the correct aspect (preterit or imperfect) than in writing the correct inflection.
Santos Gargallo (1993) examined 55 compositions written by Serbo-Croatian female university students enrolled in the third and fourth courses of Spanish. The most difficult categories included, in order: the definite article, prepositions (wrong choice), past tenses (particularly, preterit and imperfect), lexicon selection, pronouns, confusing ser/estar/haber, and gender and number agreement. Like other researchers before her (Lado 1957; Dušková 1969; Azevedo 1980), she concluded that the definite article is problematic because it does not exist in the L1. In agreement with Azevedo (1980), she found many errors in single words that have two equivalents in the L2 and suggests not to list their uses side by use in textbooks. She also noticed avoidance in the use of the subjunctive, which supports findings by Schachter (1974). Regarding gender agreement, she claims that the poor explanation found in pedagogical materials is the reason behind most errors and recommends revising and improving them.
One of the most comprehensive studies on errors is Fernández (1997). Her corpus included one composition and seven quizzes about concrete grammatical points from 108 adult learners of Spanish enrolled in courses at three different levels of proficiency. She analyzed the data in different ways (by L1, by level, across levels, etc.). Among lexical errors (13.2%), she found ser/estar as the most common. Among grammatical errors (48.2%), the most frequent errors included verbs (irregular forms, preterit/imperfect and subject-verb agreement) and prepositions (especially the “personal a”, “por”, and “en”). She found that gender agreement between the noun and the adjective was the most common error, followed by subject-verb agreement. Because of the difference between results from the compositions and results from the quizzes, she concluded that certain ethnic groups are better trained to focus on form when learning an L2, such as German and Japanese students, and do better in quizzes than in compositions. Thus, she recommends that students should be measured with a variety of tools to obtain a fairer image of their proficiency. Like Santos Gargallo (1993) and Azevedo (1980), she claims that long lists detailing different uses of two elements that have only one equivalent in the L1 are ineffective. She encourages instructors to focus on each particular item individually.
Giraldo Silverio (1997) studied the written errors that affected prepositions in adult advanced learners of Spanish of different ages and nationalities. Some of the most frequent errors included missing the “personal a”, using a preposition when it was not necessary, confusing a/en with movement and non-movement verbs, missing the “a” in the gustar structure, confusing por/para, and confusing a/para. Due to the fact that fossilization of errors occurs at early stages and that lexico-semantic changes within a preposition exist depending on the context, he recommends teachers to go over each case and exception when explaining prepositions.
Gascon (1998) focused on errors related to psych verbs (e.g., gustar, importar, interesar, etc.) produced by 105 first-, second-, third-, and fourth-semester university students of Spanish. Results showed that this structure is problematic even for fourth-semester students. Across all levels, the omission of the preposition “a” accounted for the greatest number of errors.
Madrid (1999) classified errors made by 30 English-speaking study-abroad students of Spanish. The corpus included a narration of a study previously read and sentence-completion exercises focused on categories known to be difficult for them. The most frequent errors included, in order: confusing ser/estar, wrong use of direct and indirect pronouns, wrong use of the subjunctive, omission of the article, and confusing preterit/imperfect. These errors were also present at the beginning of the program, so they persisted despite instruction and interaction with native speakers. He concludes that the reason behind most errors is the interference of the L1.
Schlig (2003) examined the errors on gender agreement made by 61 English-speaking college students enrolled in a Spanish advanced grammar course and a Spanish advanced conversation & composition course. The corpus included translations, analysis of texts, short compositions, formal essays, and answers to reading comprehension questions. Over 38% of all errors were gender-assignment or gender-agreement errors in article-noun and noun-adjective combinations. Most gender-related errors involved nouns ending in –e or consonant. Students in both courses had similar errors, implying that grammar correction makes no different in a student’s grammatical acquisition, as Truscott (1996) has always claimed. Upon examination of textbook explanations on gender, she concluded that they were not sufficient, as Santos Gargallo (1993) already pinpointed. She encourages memorization of its gender when learning a noun and suggests using “consciousness-raising tasks to help L2 learners notice grammatical gender at earlier stages” (p. 318).
Skjær (2005) examined the written answers from a high school final exam taken by 12 Norwegian students learning Spanish in Norway. She found that lexical and discursive errors impeded communication more than grammatical errors, even though these were more frequent. Like Madrid (1999) and others, she thinks that the L1 is the main source of errors.
Mohd Hayas (2006) investigated the written lexical errors found in compositions written by adult Malaysian students taking an intermediate Spanish course in Malaysia. Like other researchers (Fernández 1997; Skjær 2005), she found that errors involving grammar were more frequent (56%), with gender assignment at the top of the list.
Naranjo Hernández (2009) examined the written errors of 21 English-speaking students studying Spanish in Colombia. The most common errors were word choice and gender agreement. He supports Faingold’s (1997) position on self-correction via multiple drafts and recommends providing feedback to students as soon as possible after the task.
Martínez Guillem (2010) classified the written errors in the verbs of 20 Japanese students learning Spanish at the university. Most errors were found in grammar, particularly in subject-verb agreement, the absence of the stem-vowel change, and overgeneralization of rules. The second most frequent error was lexicon selection, particularly in words that have two equivalents in the L2, as most researchers find. He claims that knowing the L1 of the student can be useful for the teacher in order to foresee an error and strengthen that area before the error occurs.
3. The present study
The present study will examine the most common written errors made by English-speaking students learning Spanish as a foreign language at a medium-size university. Errors will be classified into lexico-grammatical categories at three levels of proficiency to extrapolate information about students’ difficulties at each level, but data will also be compared across levels to see the evolution of certain types of errors as students’ proficiency advances. Data will be also analyzed across categories at each level to obtain information on other issues that cause errors and affect more than one lexico-grammatical category, such as gender and number agreement. Because of length issues, however, only findings on the most error-bearing category, Pronouns, will be included in this article.
3.1 Participants
Participants were picked randomly from several courses at three different levels (2nd, 3rd and 4th semesters of Spanish as a foreign language). In each level, an equal amount of males and females and also a balanced representation of grades (from A through C) were selected. There were too few students with D and none with F. Therefore, those were excluded as not representative of the norm. Because errors were found by other researchers highly linked to a student’s L1, participants whose first language was not English were also excluded from the study. The final number of participants was thirty for each level of proficiency. Thus, there were ninety participants in total.
3.2 Corpus
The corpus included one element: a composition written without the help of any materials, which was part of the 3-hour final exam at each level of proficiency.
During the semester, students had written two or three compositions in class with the help of their materials, as preparation for this last final-exam composition. Each of these in-class compositions followed the discovery approach suggested by Hendrickson (1978), which has been found effective in previous studies (Faingold 1997; Lalande II 1982; Naranjo Hernández 2009). The purpose of having students to revise their first draft is to enhance students’ awareness of their own errors with the hope that they will correct them on their own if they make them again.
The second-semester course composition did not have a minimum of words required. The topic was the feature film Al otro lado [To the Other Side] (Loza 2004). Students were asked to select one of the three characters and describe him/her (using the present tense), predict what this character’s future life will be (using the future tense), and give an opinion about the movie and the theme of immigration.
The third-semester course composition required between 175 and 200 words. Students were given the option of one of two topics selected from stories read and discussed in class, such as El etnógrafo [The ethnographer] (Borges 1969), Vino de lejos [Came from afar] (Kurtz 1964), El indio y los animales [The Indian and the animals] (Rosado Vega 1934), and La conservación de Vieques [The preservation of Vieques] (extracted from a textbook by Blanco and Colbert 2008). Students were asked to write a letter pretending to be a specific character and just tell what happened in the story from his/her point of view or complain about a specific situation. Students were asked to use past tense and the subjunctive.
The fourth-semester course composition required at least 200 words. The topic was the short story Las batallas en el desierto [Battles in the desert] (Pacheco 1981). Students were supposed to select one out of two/three scenarios, such as pretending to be the female character who writes a letter to a male character, pretending to be the male character who writes his memoirs, or writing an essay about how hypocrisy is present in the short story. Students were asked to use if-clauses, as well as different tenses from the indicative and subjunctive moods.
3.3 Collection and Analysis of Data
In the present study, I used a data-driven lexico-grammatical taxonomy to identify, describe and classify the written errors of these 90 English-speaking students of Spanish. I chose this type of taxonomy because it seems to be the most practical for a teacher to extrapolate information about students’ problems in the first two years of formal instruction. In the present study, the categories that came up as the most error-bearing include –not in order-- Nouns, Verbs, Prepositions, Pronouns, Adjectives and Articles. Conjunctions and Adverbs were excluded because of their low error rate. The descriptive grammar used by the Real Academia de la Lengua Española was used as the basis to determine what an error was.
Following Fernández’s (1997) methodology, errors were counted in absolute numbers for each category (e.g., Composition 1: 6 errors in verbs, 7 errors in prepositions, etc.) to come up with a total or a global error rate. Thus, in this study, a global error rate represents the number of errors compared to the total number of words written. In addition, internal error rates were also calculated. The internal error rate refers to the number of errors vs. correct forms within a specific category. Although the global error rate is important, the internal error rate is the one that yields more information about students’ difficulties. For example, a student could make twenty errors in verbs and twenty errors in prepositions. One could think that they are equally difficult. However, when we know that he wrote a total of a hundred verbs but only thirty prepositions, those twenty errors are suddenly very different one from the other.
Errors were then classified into areas within each category depending on their nature (e.g., error in subject-verb agreement, error in the stem vowel, etc.). Appendix A shows the taxonomy with the different types of errors found. A second rater was asked to classify part of the data to enhance the reliability of the classification process. Kappa’s value was 0.895, which is considered a very good agreement.
3.4 Limitations of the Study
Spelling errors (including accents) were ignored because in a pilot study they did not help obtain any useful information regarding difficulties with lexicon or grammar. It is possible, however, that some of the errors found in a verbal ending, for example, were no more than a spelling error (e.g., Él viajo instead of Él viaja). Since the true nature of certain errors is impossible to ascertain, by general rule, errors were considered not spelling errors.
Although communicative effect, discursive errors, and mechanical errors are interesting and important too, this study focused only on lexical and grammatical errors.
In terms of design, I chose a pseudo-longitudinal design. It is longitudinal in the sense that errors are examined at different points in time (2nd, 3rd and 4th semesters), but it is not a true longitudinal study because the students are not the same individuals from beginning to end.
Another limitation of this study lies in the actual counting of errors: In order not to have negative numbers, only one error could be counted per word analyzed. That is, if a word had two errors in it (let’s say wrong stem-vowel change and wrong verbal inflection), only the most significant /serious error of the two, or the one that was found repeatedly in that particular student, was counted. Since this decision can be somewhat arbitrary, a replication study might find slightly different results in the distribution of errors by type, although it should not affect the number of errors found in a specific category.
4. Results
4.1 Global error rates and internal error rates
Global error rates for all three levels of proficiency were calculated as well as internal error rates for all categories at all levels of proficiency (see table 1).
In the second-semester course, a total of thirty compositions were analyzed. Grades included 10 students in the A range, 15 in the B range, and 5 in the C range. The total number of words written in the 6 categories selected was 4,963, out of which 559 were errors. This gives us a global error rate of 11.26% for this second-semester course. The category where most number of errors were found was Verbs, followed by Prepositions, and the single area with the highest number of errors was failing to write the “personal a”. However, when I compared errors to correct forms, the internal error rate showed that the category with the highest errors was actually Pronouns (23.35%). This was followed by Verbs (16.53%), Prepositions (15.16%), Adjectives (8.10%), Articles (7.35%), and Nouns (5.09%).
In the third-semester course, thirty compositions were analyzed. This group included 15 students in the A range and 15 in the B range. The total number of words written was 6,892, out of which 749 were errors. This gives us a global error rate of 10.87%. Again, the category with the largest number of errors was Verbs and the area with the highest number of errors was also under Verbs: lexicon selection, which includes ser/estar but dormir/dormirse, and other similar pairs. The internal error count also showed that Verbs was the category with most errors compared to correct forms (17.06%), closely followed by Pronouns (16.94%), and then Prepositions (12.58%), Adjectives (8.89%), Articles (6.57%), and Nouns (3.58%).
In the fourth-semester course, thirty compositions were analyzed. This group included twenty students in the A range and 10 in the B range. The total number of words written was 9,607, out of which 672 were errors. This gives us a global error rate of 9.28%. The category where most errors were found was Verbs again, but the area with the highest number of errors was actually found under Prepositions: lexicon selection, which includes not only por/para but also other difficult pairs such as a/en or a/para. The highest internal error rate was Pronouns (13.51%), followed very closely by Verbs (13.32%), and then Prepositions (10.72%), Adjectives (7.75%), Articles (6.51%), and Nouns (3.88%).
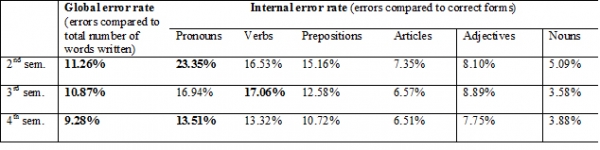
Table 1: Global error rates at each level of proficiency and Internal error rates of each category at all level